Keiko Ochi

SPEECH × WELFARE
Keiko Ochi Reserch Website
About

Project Assistant Professor, Kyoto University, Graduate School of Informatics, Speech and Audio Processing Lab. Ph. D. (Information Science and Technology)

Spoken dialogue system that is good at attentive listening
Through research on spoken dialogue, we are studying dialogue strategies that make it easier for people to talk and how listening through dialogue can encourage the users. In particular, our research group has implemented a listening robot, "Kiku Robot," which listens to a variety of people, from children to the elderly. For instance, a backchannel is a short utterance, such as "Un" (yes), that the listener utters during the interlocutor's turn to facilitate the conversation. Our research has revealed that especially in Japanese, it is important to synchronize the intensity (volume of speech).
Dialogue analysis for assessment of autism spectrum disorder
We focus particularly on the degree of similarity in speech characteristics (intonation, etc.) between the person with whom the person is speaking and the person with whom he or she is speaking, and when the person nods. We are investigating the characteristics of communication in autistic spectrum disorder, one of the developmental disorders, by analyzing speech. We focus on the degree of " entrainment," i.e., the degree to which speech characteristics (intonation, etc.) become similar to those of the interlocutor, and when nodding is performed. In the future, it will contribute to understanding the communication characteristics of people with autism spectrum disorder. In the future, we would like to apply our findings to technologies that bridge the various communication patterns toward a society with neurodiversity.
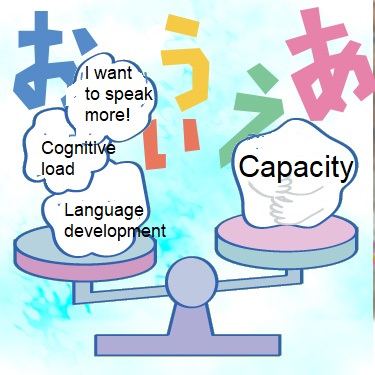
Identifying of the mechanism of stuttering (speech disorder)
Stuttering is a speech disorder characterized by symptoms of disfluency in speech (e.g., stopping at the onset or in the middle of a phrase, repeating sounds, etc.). Individuals who experience difficulties in communication and social participation require support. We study the mechanism of developmental stuttering, based on the Demands and Capacity Model (DC model). The model hypothesizes that the onset of stuttering is caused by an imbalance in young children between the desires and needs to speak from psychological and environmental aspects and the ability to physical articulation cotnrol. The DC model is a concept that has been around for 30 years. Although this model was proposed about 30 years ago as a concept, it is still unclear to what extent it is quantitatively and numerically affected by linguistic and psychological load.

Prosody (accent, intonation, and rhythm) in English learning by native Japanese speakers
While there are many factors involved in learning English, we are particularly interested in the acquisition of the fundamental frequencies (equivalent to pitch), intensity (equivalent to volume), and pauses that form prosody (accent, intonation, and rhythm), and we compare native Japanese speakers, native Chinese speakers, and native English speakers in their aloud reading of English. Japanese native speakers, Chinese native speakers, and English native speakers were compared. The results showed that Japanese native speakers were characterized by placing more pauses between words. It was also found that English native speakers have a prosody in which the fundamental frequency (pitch) and intensity (volume) are correlated, i.e., where the fundamental frequency is high, the intensity is also high, whereas English spoken by Japanese native speakers does not show such a correlation.
Detailed inforamtion(researchmap)
- Ochi, K., Ono, N., Owada, K., Miho, K., Sagayama, S., & Yamasue, H. (2022). Use of Nods Less Synchronized with Turn-Taking and Prosody During Conversations in Adults with Autism}}. Proc. Interspeech 2022, 1136-1140.
- Ochi, K., Ono, N., Owada, K., Kuroda, M., Sagayama, S., & Yamasue, H. (2022, May). Entrainment analysis for assessment of autistic speech prosody using bottleneck features of deep neural network. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 8492-8496). IEEE.
- Ochi, K., Kojima, M., Owada, K., Ono, N., Sagayama, S., & Yamasue, H. (2021, December). Pitch and Volume Stability in the Communicative Response of Adults with Autism. In 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (pp. 428-432). IEEE.
- Fukunaga, D., Ochi, K., Obuchi, Y., (2021). Development of Automatic Chart Generation System for Rhythm Action Games Using Key-sounds.The IEICE transactions on information and systems (Japanese edition) D, 104(12), 818-829.
- Arongna, Ochi, K., Sakai, N., Hatano, H., Mori, K., (2021). Articulation Rate of People Who Do and Who Do Not Stutter: Comparison between Oral Reading and Speech Shadowing. Journal of the Phonetic Society of Japan, 25, 1-8.
- Ochi, K., Ono, N., Owada, K., Kojima, M., Kuroda, M., Sagayama, S., & Yamasue, H. (2019). Quantification of speech and synchrony in the conversation of adults with autism spectrum disorder. PloS one, 14(12), e0225377.
- Ochi, K., Mori, K., & Sakai, N. (2018). Automatic Evaluation of Soft Articulatory Contact for Stuttering Treatment. In INTERSPEECH (pp. 1546-1550).