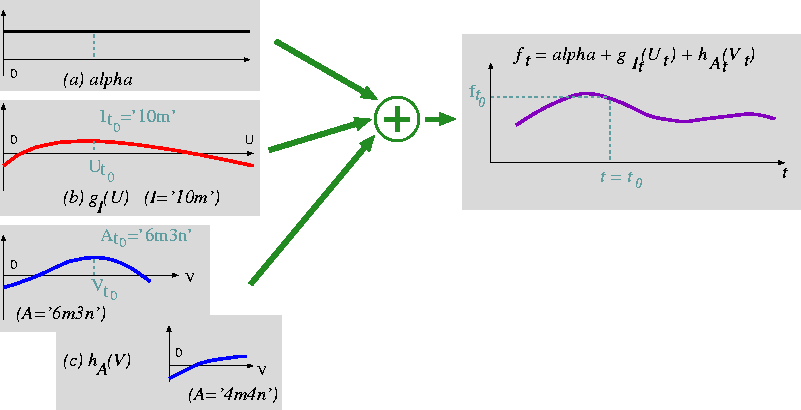
Figure 1: A schematic diagram of the additive F0 model.
|
Figure 1: A schematic diagram of the additive F0 model. |
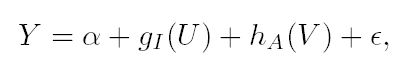 (1) (1)
|
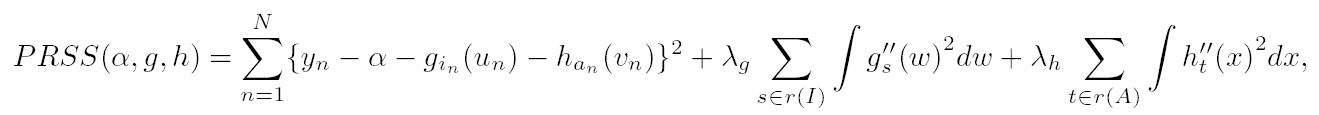 (2) (2)
|
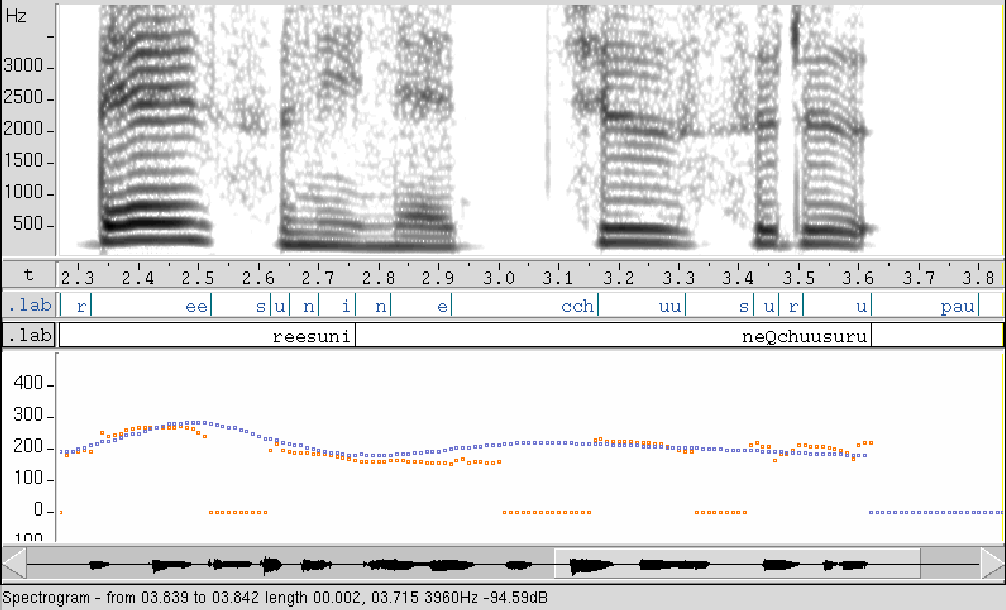
Figure 2: F0 contour from the model, displayed with the actual F0 contour. The orange dots are the F0 data in the test data, and the blue dots are the F0 contour derived from the additive F0 model |
| Last update: 7/30/2004 |